Benchmarking Reader-Writer Lock Performance
This post presents benchmark results for two popular reader-writer lock implementations, and offers some (tentative) explanations for the patterns we observe.
Motivation: Why Benchmark Reader-Writer Locks?
A project with which I am involved currently uses tbb::reader_writer_lock from Intel’s Threading Building Blocks (TBB) library to back its internal “shared lock” implementation. However, the TBB library recently (as of this posting) deprecated its tbb::reader_writer_lock type, and now suggests that users replace this type with the C++ standard library’s std::shared_mutex. Before going ahead with this change, I was curious as to what performance differences (if any) it implied, but direct comparison of the performance characteristics of these two lock implementations proved elusive.
This post is far from the final word in reader-writer lock performance evaluation, but I hope it does serve as a starting point for others looking into similar evaluations.
Introduction: Reader-Writer Locks
A Reader-Writer Lock is a synchronization primitive that provides mutual exclusion. Like their more popular cousin, what I will refer to as a “vanilla” lock, they support the ability to acquire the lock in an exclusive mode - only one thread may own the lock at any one time. However, as their name suggests, reader-writer locks also provide the additional ability to acquire the lock in a shared mode wherein many threads may own the lock for read-only access to the protected data at the same time. The API for a reader-writer lock RWLock might therefore look something like:
RWLock::lock_shared()- Acquire the lock in shared modeRWLock::lock_exclusive()- Acquire the lock in exclusive modeRWLock::unlock_shared()- Release the lock held in shared modeRWLock::unlock_exclusive()- Release the lock held in exclusive mode
The API provided by various implementations may differ slightly from this archetype, but the methods above present the general idea.
The benefit of reader-writer locks over vanilla locks is that they provide the ability to increase the level of concurrency supported by an application. In the event that operations on the data protected by the lock do not involve mutation, they may be safely performed concurrently by multiple threads.
Reader-Writer Lock Implementations
We’ll look at two popular reader-writer lock implementations in this benchmark:
tbb::reader_writer_lock
The reader-writer lock implementation from Intel’s TBB library serves threads on a first-come first-served basis, with the added caveat that writers are given preference over readers - this is often an important modification to ensure that writers are not starved in read-heavy workloads. All waiting is done in userspace via busy-loops. This design is a double-edged sword: under low contention, this saves us potentially-expensive calls into the OS kernel, but under high contention this might lead to significant performance degradation as multiple cores are saturated with threads spinning on the lock.
std::shared_mutex
The standard library’s reader-writer lock implementation necessarily differs among compilers and platforms. For this benchmark I utilize a system with the following relevant specifications:
- Compiler: GCC 10.2
- Standard Library:
libstdc++ - Operating System: Ubuntu 18.04
Under this configuration, std::shared_mutex is backed by pthread_rwlock_t from the Pthreads library. Unlike tbb::reader_writer_lock, pthread_rwlock_t uses an adaptive locking approach - the implementation consists of a “fast path” in which waiting threads busy-loop in userspace, eliding a call into the kernel, and a fallback mechanism in which the call into the kernel is performed, allowing threads to wait on the lock without spinning (on Linux this is implemented via the futex system call).
The above descriptions should make it evident that the two reader-writer lock implementations differ considerably. But which implementation performs better, and under what conditions?
Benchmark: Setup
All of the code used to benchmark the performance of these two reader-writer lock implementations is available on Github.
To evaluate the performance of these lock implementations, we focus on two important runtime properties: throughput and latency. In this context, throughput refers to the number of lock requests we can process in a given amount of time. In contrast, latency measures the time interval between when a thread requests the lock (in either shared or exclusive mode) and when the request is granted. Both of these performance characteristics are important to the overall performance of a program, but the degree to which this is true depends heavily on the specific requirements of the application.
Benchmark: Results
Throughput
For throughput evaluation, we benchmark both lock implementations under two workload characteristics:
- read-heavy represents a theoretical workload in which 10% of lock requests are for exclusive access and the remaining 90% of requests are for shared access.
- equal-load represents a theoretical workload in which the number of exclusive and shared lock requests are equivalent.
For each of these workload characteristics, we vary the total number of worker threads running the benchmark (contending on the lock) and measure the total time required for all workers to complete the prescribed number of operations with the lock held. The results are summarized by the plot below.
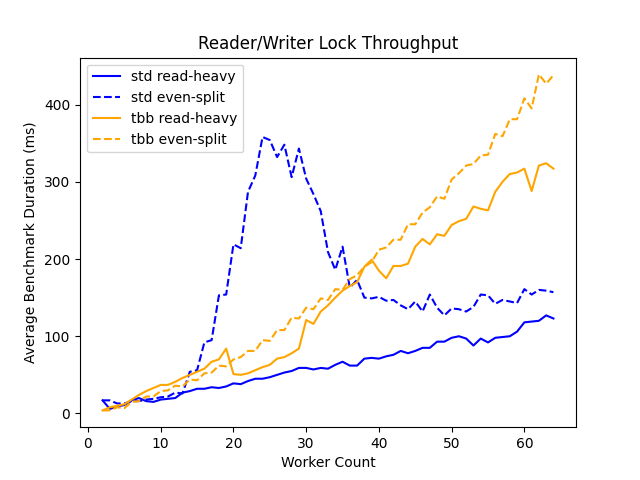
We observe a couple interesting trends here. First, as expected, throughout declines (total benchmark duration increases) between ready-heavy and equal-load workloads - this result is intuitive because we expect to achieve a higher level of concurrency on the read-heavy workload as a larger number of threads are permitted to own the lock concurrently.
The other trend that stands out is the shape of the curve for std::shared_mutex under the equal-load workload - we see a massive spike in the time required to complete the benchmark between 20-40 worker threads, diverging significantly from the pattern observed for the read-heavy workload. We’ll revisit this anomaly below.
Latency
As in the throughput evaluation, we measure latency under both read-heavy and equal-load workloads. Here, the two workloads are separated into distinct figures because we plot the average latency experienced by reader and writer threads separately, and combining all of these results into a single figure becomes unwieldy.
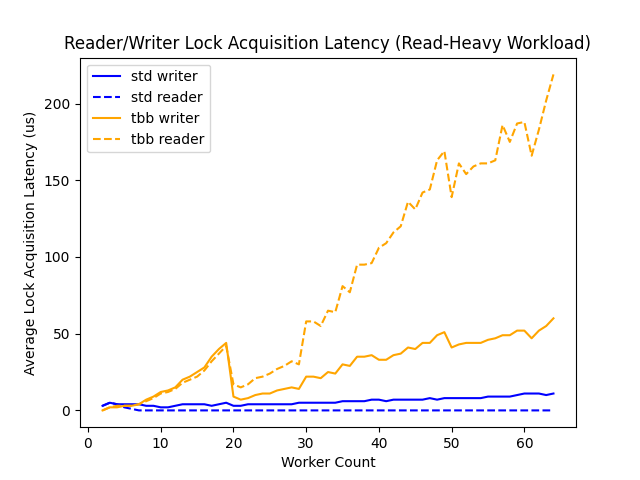
Here, the most noticeable trend is the increase in read-latency in the tbb::reader_writer_lock implementation relative to write-latency. What we are likely observing is the effect of the writer-preference heuristic in tbb::reader_writer_lock - as the number of worker threads increases, a large proportion of which are readers (90%), a single writer prevents many reader threads from acquiring the lock, and the effect may be amplified as additional writers are added to the benchmark.
In contrast, the latency experienced by readers under std::shared_mutex is nearly constant, suggesting that pthread_rwlock_t either does not include similar provisions for preferring requests from writer threads, or implements a more advanced policy that bounds this latency.
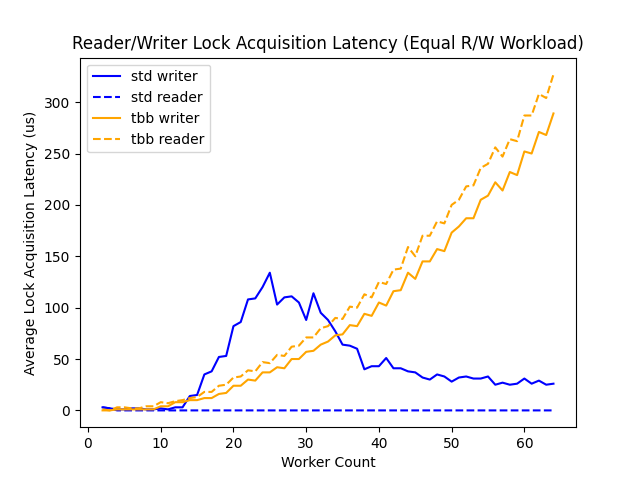
As in the read-heavy workload, we see that the latency of operations on std::shared_mutex is significantly lower than the corresponding latency associated with tbb::reader_writer_lock. Furthermore, we observe the same strange performance behavior that we observed in the throughput experiment for std::shared_mutex as the latency experienced by writers increases sharply between 20-40 worker threads before descending to a more reasonable level. This unexpected performance degradation may be a result of either some heuristic within the implementation of pthread_rwlock_t or an artifact of the hardware characteristics of the system on which this benchmark was run - repeating the benchmark on a system with a different hardware profile might clarify this issue.
Analysis and Conclusions
The overall character of the above results suggests near-universal supremacy of std::shared_mutex relative to tbb::reader_writer_lock:
std::shared_mutexdemonstrates higher throughput in the general case, the obvious exception being for a moderate number of worker threads on equal-load workloadsstd::shared_mutexdemonstrates not only lower absolute lock acquisition latency thantbb::reader_writer_lockbut also a latency that scales much more favorably with increasing contention on the lock
If you’re anything like me, you might be surprised by these results. Because tbb::reader_writer_lock uses busy-waits to avoid calls into the kernel, I expected it to outperform std::shared_mutex on both throughput and latency metrics up through a moderate level of contention. Instead, we observe that for all but the lowest levels of contention, std::shared_mutex dominates along both of these dimensions. To what might we attribute these results?
Without the source of tbb::reader_writer_lock available for review, the best we can do is speculate. However, I am confident that the issues with spinlocks highlighted by Malte Skarupke in his popular post on the subject provide at least part of the explanation. In his post, Malte is primarily concerned with the “worst-case” latency for acquire operations on spinlocks, but in the process he (convincingly, in my opinion) demonstrates how busy-loops in userspace can wreak havoc with the OS scheduler and produce surprisingly poor performance. Malte’s analysis is specific to the default scheduler implementation in the Linux kernel, and he demonstrates that utilizing different schedulers significantly influences spinlock performance. Because there is little difference between a “vanilla” spinlock and the spinning performed by tbb::reader_writer_lock, we may be observing a similar phenomenon in these benchmarks.
Linus Torvalds responded to Malte’s post by claiming that the fault lay in the use of spinlocks in the first place, and not any shortcomings of the Linux scheduler. In his rebuttal, Linus suggests that lock implementations that interact with the OS (e.g. adaptive locks like std::shared_mutex) are almost always a better choice than spinlocks because they necessarily work with the underlying OS scheduler rather than “confusing” it by appearing to be performing useful work when in reality they are waiting for a lock to be released.
Perhaps it was observations like these that led Intel to deprecate tbb::reader_writer_lock in the first place. The library’s maintainers may have concluded that the number of instances in which locks implemented via busy-waiting alone are competitive with adaptive locks is so vanishingly small that the type was no longer worthy of inclusion.
In any event, after performing these benchmarks I feel comfortable replacing tbb::reader_writer_lock with std::shared_mutex, and even feel relatively confident that the overall performance of the application will be improved by this change. Cheers to the team at Intel for making intelligent deprecation decisions.